 Book Recommendation System
Book Recommendation System
Production-grade hybrid recommender with warm/cold support, real-time similarity search, and daily retraining with hot reloads.

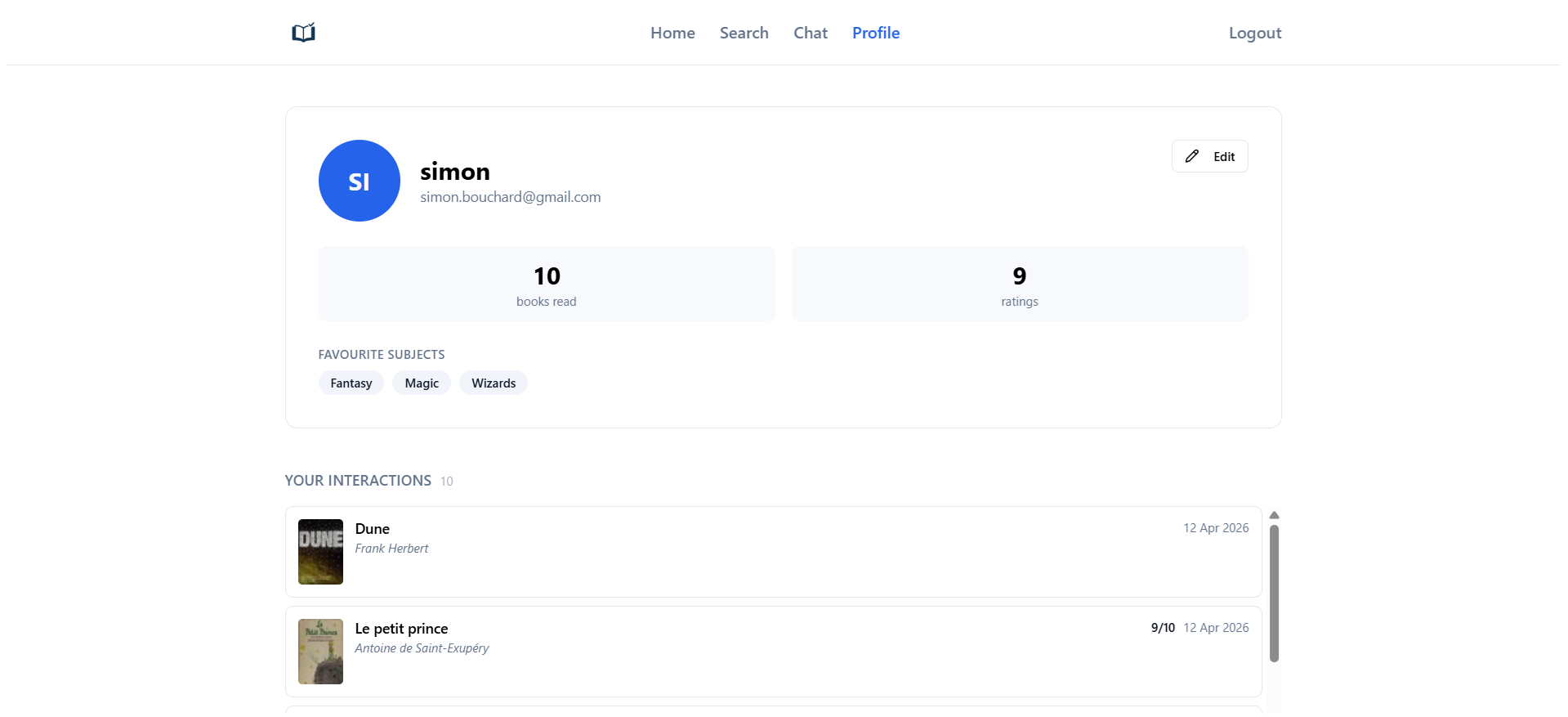
Overview
A production-grade recommendation engine that supports both warm users (with prior ratings) and cold users (no history). It serves personalized recommendations and item similarity search with low latency, and runs on a fully automated pipeline with daily retraining and hot-reload of new artifacts.
Capabilities
- Serve warm users via ALS collaborative filtering
- Serve cold users via subject embeddings and a Bayesian popularity prior
- Provide item similarity (ALS, subject, or hybrid) with adjustable weights
- Automate data export, training, and deployment with safe, zero-downtime reloads
Why this dataset (and why messy on purpose) I intentionally built on the classic Book-Crossing dataset, which is older and deliberately rough around the edges: it was crawled in 2004, ships with minimal metadata (no tags/subjects), many missing demographics (age/location often null), and historically inconsistent ISBNs that require validation/cleanup. That made the project harder—but closer to real life, where companies struggle to operationalize AI on top of noisy, inconsistent databases. Working through enrichment (Open Library subjects), ID normalization (ISBN → work_id), and strict split-safe aggregates prepared me for those production realities.
Recommendation Engine

Embeddings
The system uses two types of learned representations:
- ALS factors (collaborative): user and item vectors learned from interaction patterns via Alternating Least Squares. Captures behavioral similarity (same author, series, reading patterns).
- Subject embeddings (content): each of ~1,000 subjects has a learned embedding. Books and users are represented by attention-pooled aggregates over their subjects. Trained with a dual loss: regression on ratings anchors embeddings to actual taste signals, and contrastive loss on subject co-occurrence captures semantic relationships between subjects without explicit labels.
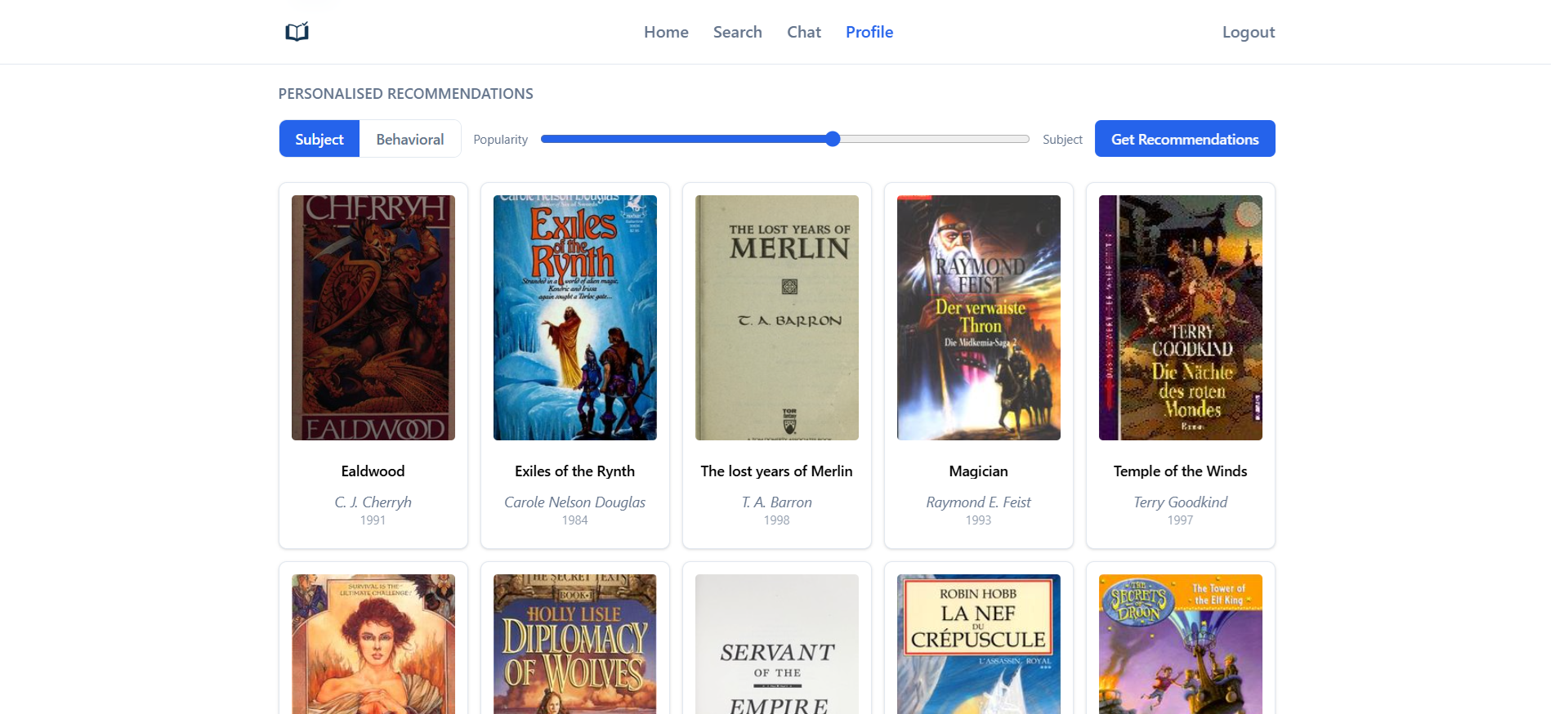
Recommendation modes
- Warm users (have prior ratings): ALS factors retrieve top candidates from collaborative signals.
- Cold users (no ratings): subject embeddings compute similarity between the user’s favorite subjects and all books, combined in parallel with a Bayesian popularity prior (user-adjustable weight). If the user has not chosen any subjects, the system falls back to popularity-only rankings.
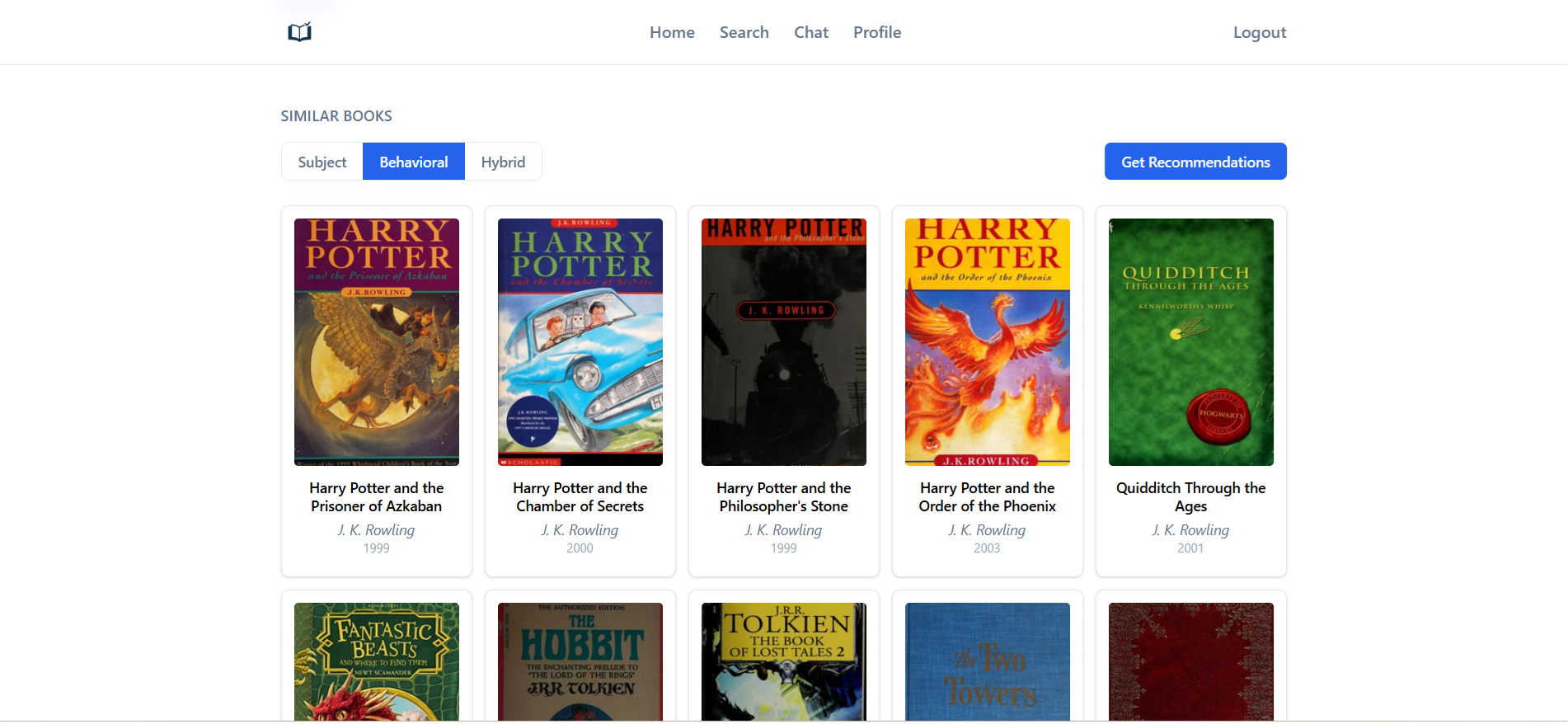
Item similarity modes
- ALS (behavioral): strong for same-author or series; weaker on sparse or niche items.
- Subject (content): broader coverage; slightly noisier on books with many subjects.
- Hybrid: weighted combination of both, adjustable at query time.
Model servers
ML models are split across 5 independent services, each owning a non-overlapping set of artifacts. The separation minimizes memory footprint (no artifact duplication across processes) and mirrors how a scaled deployment would distribute work across hosts:
- Embedder: attention-pooled subject embeddings (PyTorch)
- Similarity: subject HNSW index, ALS HNSW index, hybrid FlatIP index
- ALS: user/item factors, warm-user detection
- Metadata: book metadata lookup, Bayesian popularity scores
- Semantic: FAISS vector index for semantic search
Single-index lookups use HNSW for fast approximate search. Hybrid similarity blends subject and ALS score vectors at query time and requires a FlatIP index because HNSW does not support the inner product scoring needed to correctly combine two score vectors.
Subject Embeddings
Training objectives
- Regression (RMSE) on ratings to align embeddings with observed preferences.
- Contrastive loss on subject co-occurrence to improve neighborhood quality.
Attention pooling
- Weights the most informative subjects per book or user.
- Per-dimension attention was chosen over scalar (better recall, negligible latency cost) and transformer self-attention (required significantly more parameters and tuning to meaningfully outperform per-dimension, at higher serving cost).
Automation & Deployment
- Data pipeline: normalized SQL schema (users, books, subjects, interactions).
- Training pipeline: scheduled daily via a systemd timer. The pipeline is linear (9 steps) and simple enough that a full orchestrator like Airflow would add infrastructure without much benefit. Systemd handles scheduling, restarts on failure, and email notifications.
- Quality gate: before promoting new artifacts, recall@30 is evaluated on the full training set. If it falls below threshold, the new version is blocked and a failure notification is sent.
- Hot-reload: each model server reloads from a shared version pointer file. The training pipeline writes a new version and signals all 5 servers independently, with zero downtime.
- 5 model servers: each owns a non-overlapping set of artifacts, minimizing memory footprint and mirroring how a distributed deployment would partition work across hosts.
- FastAPI backend: paginated endpoints, caching, and auth; served via Gunicorn + Nginx.

Inference pipeline
Both recommendation and similarity paths check the Redis cache first; on a miss the pipeline runs and the result is written back before returning. The filter (remove already-read books) and metadata enrichment steps in the recommendation path run concurrently via asyncio.gather since both only need the candidate ID list. This reduces the combined cost from roughly sequential to the max of the two, cutting the tail significantly.

Semantic Search & Information Enrichment
The chatbot’s recommendation agent uses semantic vector search to interpret natural language queries and return catalog-grounded results. The search is powered by LLM-enriched book metadata.
Enrichment pipeline Before embedding, each book is tagged with subjects, tone, genre, and vibe by a small LLM. To contain hallucination on sparse books (roughly half the catalog), an information availability score is computed per book from description length and Open Library subject count. Books are bucketed into quality tiers: richer books produce more tags; sparse books produce fewer or none. The model only generates what the available metadata can support, which improved retrieval quality over the naive approach of prompting uniformly.
The enrichment ran once over ~250k books using an Ollama 3–7B model via API. Running a model locally was not feasible given the server’s resources, and using a larger model or adding web search access would have reduced hallucination more effectively but at prohibitive cost at this scale (GPT-4o would have been hundreds of dollars). The data quality tier approach was the cost-constrained workaround: the 3–7B model completed the full run for $5–10, and restricting output quantity by available metadata kept hallucination contained without discarding good output for well-documented books.
The pipeline was built with Kafka and Spark, partly because remaking the enrichment layer coincided with learning those tools, and the structure supports incremental re-runs.
Chatbot
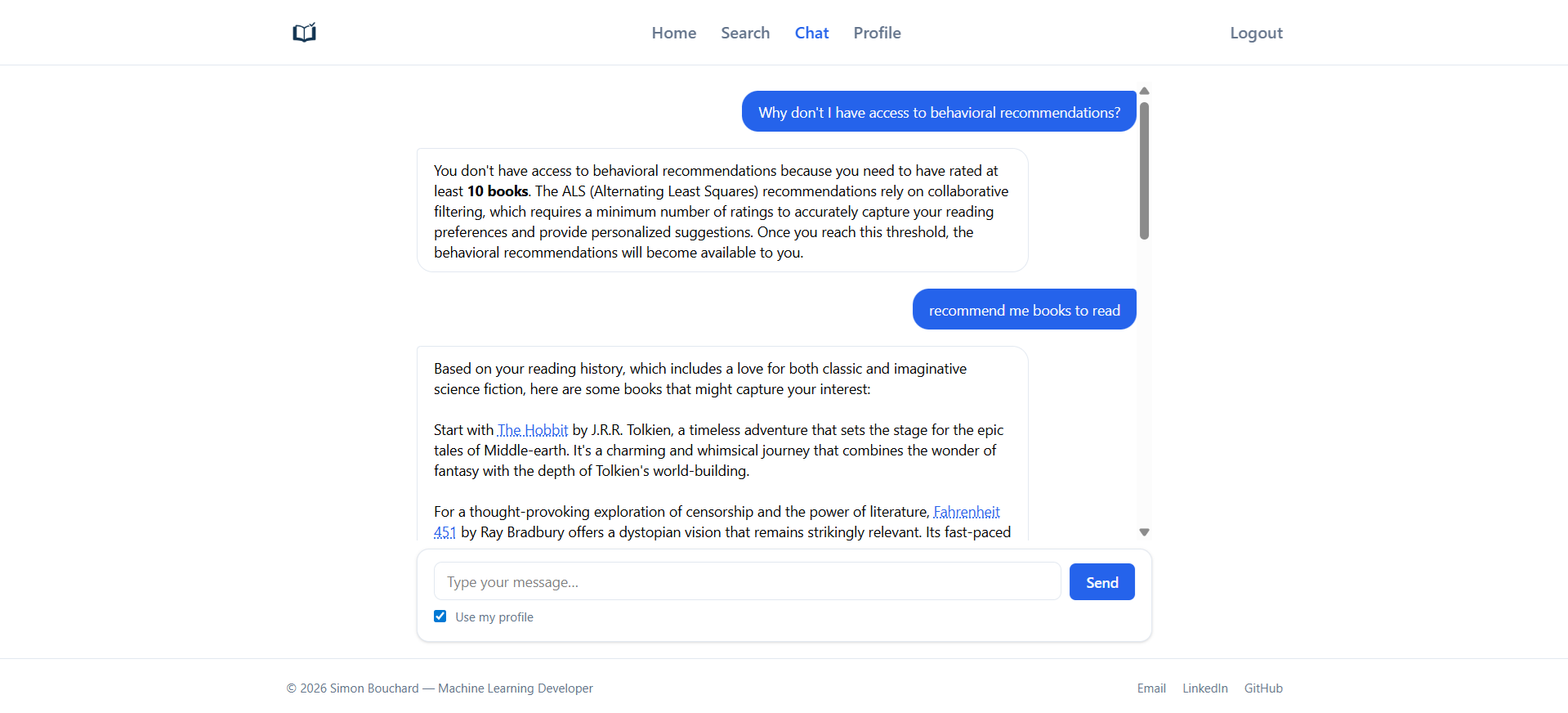
The integrated chatbot is a multi-turn virtual librarian built with LangGraph.
Architecture A central Router classifies the intent of each message and dispatches it to one of four specialized agents:
- Response agent: handles direct answers, greetings, and clarifications requiring no tool use.
- Docs agent: answers questions about the platform (ReAct loop).
- Web agent: external lookups for recent or out-of-catalog books (ReAct loop).
- Recommendation agent: multi-stage pipeline: planning → retrieval → selection → response.
The Recommendation agent is the most complex. A Planner selects which retrieval tools to call; a Retrieval step executes them (ALS, subject similarity, semantic search); a Selection step filters and ranks candidates; a Response step generates the explanation.
Responses are streamed to the client via SSE. Conversation history is stored in Redis per session, with per-user rate limiting enforced independently.
LLM cost tradeoff Complex agents (recommendation, docs, web) use GPT-4o where reasoning quality and instruction-following matter. Simpler agents (router, planner, response) use Ollama 70B via API, sufficient for structured classification and planning tasks at a fraction of the cost.
Why LangGraph The chatbot started as a raw LangChain chain. As it grew multi-agent, the volume of custom routing and state management code became hard to maintain. Switching to LangGraph (which models the agent graph explicitly) replaced most of that boilerplate and significantly reduced the overall codebase.
Users can opt in via a UI toggle to share their profile (favorite subjects and reading history) with the agent, personalizing both candidate retrieval and the generated prose.

Observability
Metrics (Prometheus + Grafana)
- Request counters and latency histograms per path (recommendations, similarity, search, chat).
- Drift monitoring tracked on every request with zero added latency: score distribution histograms, result count distributions, and empty-result rate counters. Alert rules fire when any metric crosses a per-mode threshold.
- Click-through rate tracked per recommendation surface (recommendations, similar, chatbot) and mode to measure model usefulness from actual user behaviour.
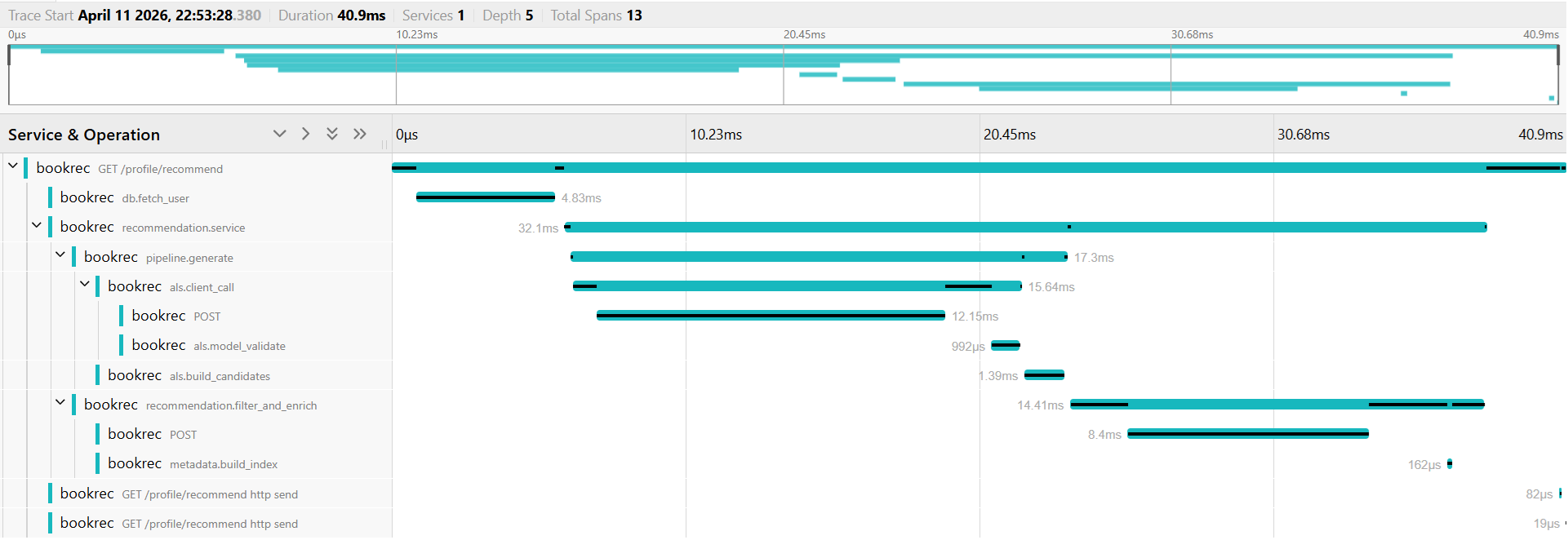
Distributed tracing (OpenTelemetry + Jaeger)
- Auto-instrumented for FastAPI, httpx (model server calls), and SQLAlchemy.
- Manual spans added at service and pipeline boundaries, including the full chatbot pipeline (router classification, each agent, all four recommendation stages, and per-tool spans). Trace context propagated across the SSE streaming boundary so all spans remain correctly parented.
CI/CD
GitHub Actions runs on every push and pull request:
- Backend: ruff lint and format check, pytest unit tests.
- Frontend: ESLint, TypeScript type check, Vite build.
- Deploy (master push only, after both pass): SSH trigger runs a deploy script on the production server: git pull, frontend build, service restart, health check loop.
Testing & Evals
Tests are organized into three layers.
Unit tests (run in CI) cover the recommendation pipelines, ranker and filter logic, all 5 model server HTTP handlers, the HTTP client layer, artifact registry and path resolution, and the training quality gate. All I/O and ML dependencies are mocked.
Integration tests require the live system with model servers running and artifacts loaded. They verify response contracts (warm/cold routing, score sort order, k-bound enforcement) and include latency benchmarks per endpoint. Chatbot integration tests cover multi-turn state, context builder correctness, error boundaries, and concurrency.
Agent evaluations are an LLM-judged suite organized by use case with multiple scored examples per case. Each stage of the recommendation agent is evaluated separately and end-to-end:
- Planner: compared against expected tool selections; no LLM judge needed since output is structured JSON.
- Retrieval: verifies plan adherence, correct tool arguments, error recovery, and adaptive strategy when initial results are poor.
- Selection: verifies output count, no duplicates, no more than two books per author, and negative constraints respected.
- Response: LLM judges score the opening paragraph, per-book descriptions, and closing paragraph against specific criteria.
Results are tracked with a comparison dashboard that diffs each run against the previous one.
Data & Processing
The original Book-Crossing data is noisy (ISBN variants, duplicates, missing metadata, no subjects). The pipeline cleans and enriches it using Open Library and internal rules.
-
ID normalization & edition merging
- Normalize ISBNs → map to Open Library work_id.
- Merge editions under a single work_id to consolidate interactions.
- Assign a stable integer item_idx for modeling and serving.
-
Subject enrichment & reduction
- Pull subjects from Open Library per work.
- Reduce ~130,000 raw strings to ~1,000 usable categories via cleaning, deduplication, and frequency filtering.
- Maintain a vocabulary mapping
subject_idx → subject.
-
User data cleaning
- Clean ages (remove extremes, bucket into age groups).
- Normalize locations (extract country).
- Derive favorite subjects (top-k) for cold-start embeddings.
-
Ratings cleaning
- Enforce valid rating ranges.
- Drop duplicates.
- Filter users/books with too few interactions to stabilize training.
-
Subject & metadata normalization
- Store
subjects_idxsas fixed-length padded lists. - Exclude generic categories (“Fiction”, “General”) from main_subject.
- Canonicalize authors/years/pages (e.g., “Unknown Author”, year buckets, imputed pages).
- Store
-
Aggregate features
- Precompute book/user aggregates (count, average, std).
- Export together with embeddings to keep training/inference consistent.
-
LLM-agent enrichment
- For each book, an LLM agent constructs a structured dictionary describing the work (themes, tone, style, audience, etc.).
- Inputs: normalized DB info (title, author, year, subjects, aggregates) + optional external lookups (agent can call a capped set of web tools if metadata is sparse).
- Outputs: validated, schema-locked dictionary fields.
- These dictionaries are stored alongside SQL metadata and form the basis for LLM-based book embeddings and vector search.
Result: a clean, normalized SQL schema with stable IDs, consistent metadata, and a compact subject vocabulary that powers both collaborative and content-based models.
Research & Experiments
Retrieval architectures GBT rerankers on top of ALS were explored but dropped: the available user metadata was too sparse to add meaningful signal (age 50% missing, location 97% from one region), so the reranker did not improve recall while adding latency. Residual MLPs and two-tower architectures both worked but showed the same pattern: added latency without improving recall over a simpler dot-product approach. The final stack pushes complexity into training and keeps inference to dot products and matrix lookups at serving time.
Cold-start embeddings Clustering and regression over user metadata were tried first. With metadata this sparse, results were poor: regression embeddings collapsed toward the global average, and clustering assigned most users to the same popular cluster. Subject-preference embeddings derived directly from favorite subjects generalized much better.
Attention pooling Scalar, per-dimension, and transformer self-attention were all evaluated. Per-dimension attention outperformed scalar with virtually no added latency. Transformer self-attention required significantly more parameters and tuning (heads, layers) to meaningfully outperform per-dimension, at higher serving cost. Per-dimension was the clear choice.
Biggest mistakes & what I learned
1) No fixed validation early on → aggregates caused leakage (and weeks of wasted experiments)
What I did: I didn’t lock a validation set at the start. I computed aggregates like user/book avg/count/std on the full data and then split, which bled information from val into train-time features.
Symptoms I saw: Validation RMSE looked great; when I finally evaluated on a leakage-free test set, performance collapsed (RMSE drifted back near the ratings’ std dev). Many “wins” were artifacts of leakage.
Impact: I spent a lot of time comparing models on a false signal. Tuning decisions and exploratory work were based on numbers that wouldn’t hold up.
Fix: I rebuilt the dataset pipeline:
- Predefine train/val/test (time-aware and/or user-stratified where relevant).
- Compute aggregates within split (or with time cutoffs so no look-ahead).
- Version artifacts by split and timestamp; store
split_idwith every export. - Add an early, single sanity run on test with a simple baseline (e.g., popularity/ALS) to catch pipeline bugs without gaming the test set.
Lesson: A good validation split is not optional. Build features in a way that cannot see beyond the split boundary. And while you must avoid overfitting to test, one early, baseline test check is worth it to verify the pipeline isn’t lying.
2) Optimizing RMSE for a ranking problem (and judging components instead of the pipeline)
What I did: I tracked retrieval metrics (Precision/Recall/MAP/NDCG) for ALS early on, but I didn’t hold the entire pipeline (ALS → reranker) to the same standard. For subject embeddings, I initially evaluated by RMSE rather than by neighborhood quality for similarity/retrieval.
Impact: Objective/metric mismatch. Embeddings that looked fine under RMSE didn’t produce clean neighborhoods for FAISS, and pipeline decisions weren’t aligned with the real serving goal (top-K ranking).
Fix: I aligned training and evaluation with how the system serves results:
- Trained embeddings with a dual objective: rating regression (RMSE) plus a contrastive loss over batch co-occurrence to encourage useful geometry.
- Evaluated end-to-end (candidate generation + reranking) with ranking metrics like Recall@K / NDCG@K, not just component-level RMSE.
Lesson: Optimize for what you ship. When the product is a ranked list, rank-aware objectives and metrics should lead. After the change, FAISS neighborhoods were much cleaner and ranking quality improved. In hindsight, many of the earlier “fancy” notebook ideas would likely have had a better chance with the improved embeddings and geometry-focused training—the groundwork matters.
3) Indexing before splitting (development-time) → untrained embeddings to filter
What I did (during development): Early on I precomputed indices (subjects/categories, items) on the entire dataset, and only then created train/val/test splits. That meant my vocabularies contained entries that never appeared in the training fold.
Impact: I was aware of the issue, but it still cost time. Some embedding rows existed (initialized) but were never trained because their items/subjects appeared only in val/test. I had to make absolutely sure the pipeline filtered out untrained vectors everywhere—otherwise they would introduce noise and worsen metrics.
Fix: I rebuilt the dataset with a “split-first” approach:
- Define and freeze splits up front.
- Build vocabularies/indices per split (or with strict time/split cutoffs).
- Materialize embeddings only for IDs present in that split.
Lesson: Derive vocabularies after you define splits. Even if you notice the problem, the time sink of downstream filtering is real—and unfiltered rows quietly hurt retrieval quality.
4) Delaying LLM-agent enrichment → missed leverage
What I did: Performed enrichment (e.g., subjects, metadata cleanup) but didn’t bring in LLM agents early enough to structure and enrich book data. Impact: Without agent-based enrichment, inputs stayed thin and uneven. Downstream models (ALS explanations, subject similarity, early retrieval trials) were bounded by this. Fix: Use carefully prompted LLM agents earlier in the pipeline to normalize and expand metadata (tone, themes, target audience, etc.), combining local DB fields with limited external lookups. Lesson: Agent-led enrichment/cleaning is now part of data engineering. Starting earlier means stronger, more consistent inputs that lift every downstream stage (ALS, subject embeddings, vector search, RAG answers).
Meta-lessons I’m taking forward
- Split first, then feature. Leakage prevention by construction beats detection after the fact.
- Baseline early, once. A single early test pass with a simple model can save weeks.
- Evaluate what you serve. Measure candidate gen + reranking with ranking metrics; use RMSE (or MAE) only where it truly reflects the objective.
- Make it cheap to rebuild. When fixes require re-exports, fast, reproducible pipelines keep momentum.
Tech Stack
Python, FastAPI, PyTorch, FAISS, Implicit (ALS), Sentence-Transformers, SQL (MySQL), Redis, Meilisearch, Nginx + Gunicorn, Systemd, LangChain, LangGraph, OpenTelemetry, Prometheus, Grafana, Jaeger, Kafka, Spark, Docker, GitHub Actions.